

This project report was compiled as part of the course requirements of CS 6476 Computer Vision under Prof. James Hays
In this project, we use computer vision to detect faces in images and draw bounding boxes around them to highlight the detection. The problem is solved as a Supervised Classification Problem
Algorithm
We do the above based on the Dalal & Triggs method, which was used for human detection, but it is applciable to various other scenarios like face detection.
- The algorithm is provided a huge number of positive(faces) and negative samples.
- For each of the samples, a Histogram of Oriented Gradients is computed.
- The features are labelled as positive and negative and are separated using an SVM.
- The weights obtained by the SVM can now be used to detect faces in the test data set.
Feature Computation
Histogram of Oriented Gradients
HoG is a local descriptor much like the SIFT feature, except that the it is direction invariant, i.e. A Gradient at an angle of 35 degrees creates the same effect as a gradient at an angle of 215 degrees.
The method was patented by Robert K. McConnell of Wayland Research Inc. in 1986 but the usage became widespread in 2005 only after Navneet Dalal and Bill Triggs, researchers for the French National Institute for Research in Computer Science and Automation (INRIA), presented their supplementary work on HOG descriptors at the Conference on Computer Vision and Pattern Recognition (CVPR). In this work they focused on pedestrian detection in static images
High-level overview of the Algorithm
- The image is broken down into overlapping blocks and each block is further split into 2x2 cells
- The directions are discretized into 9 orientations
- Concatenating each of these histograms, we get a feature for the block of 36 (2x2x9) dimensions
- The binning is not strictly discreet, in the sense that, gradients, contribute a magnitude proportional to the projection on the neighbouring directions. The HoG per block is normalized to make the feature insensitive to constant intensity changes
- The HoG of the image is the concatenation of histograms of such blocks
A detailed step by step implementation guide can be found here

Image courtesy of Vlfeat
In our case, we use the Vlfeat implementation of HoG which uses the Felzenszwalb implementation which is a 31 dimension vector instead of 36. The Felzenszwalb implementation computes both, the directed and undirected gradients as well as four dimensional testure-energy feature, but projects them on a 31 dimensional feature vector.
The training set is divided into 2 sets, positive and negative images. The positive training set contains images of faces trimmed at their bounding boxes. The negative training set contains images which do not contain any faces. This negative set is used to generate more negative image samples, by rescaling the images and computing HoGs of these images.
Classifier training
The hog features obtained from the positive and negative images are then passed on to a SVM to compute the parameter vector W and the bias b. These parameters can now be used to detect faces in the test set images
Prediction
Sliding Window
A sliding window is a mask which returns a piece of the image. Sliding refers to the translation of the mask along the image.

A HoG of the image returned by the sliding window is computed. Based on the obtained Hog, W and b values, a prediction is made for the image in the sliding window.
\[y = W . HoG(image) + b\]The values of y is used as a metric of confidence for the sliding window to be considered as a face. The y values above a certain threshold are passed back as positive matches by the detector
Results
The following was obtained as the best performance with the above pipeline. The parameters of the system are:
| SVM Lamda | 0.000001 |
| Negative Sample Count | 10000 |
| HoG Cell Size | 3 |
| HoG Template Size | 36 |
| Accuracy Obtained | 91.6% |
 |
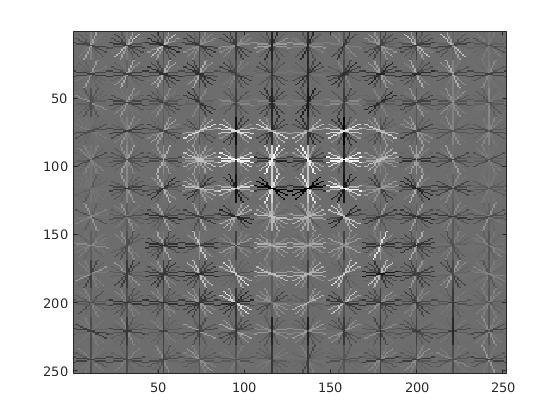 |
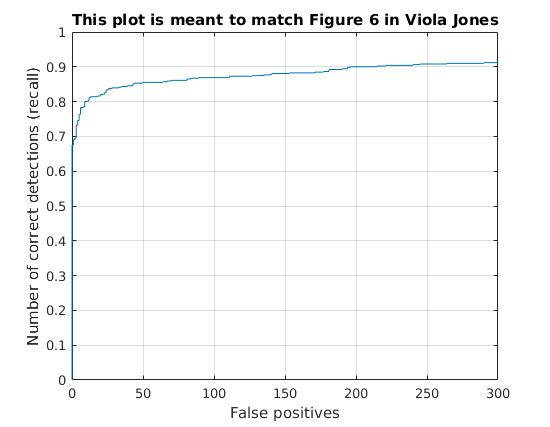 |
Experimentation
Negative Features Count
The following experiments were performed with a cell Size: 6 due to memory constraints
| Negative Feature Size | Accuracy | Time(s) | AP Curve | HoG Feature |
|---|---|---|---|---|
| 5000 | 86.3% | 16 |  |
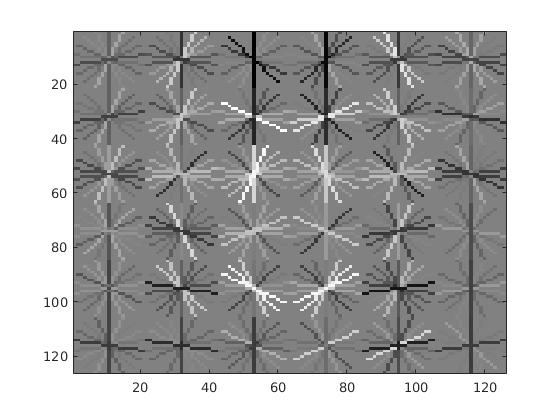 |
| 10000 | 86.3% | 4.5 |  |
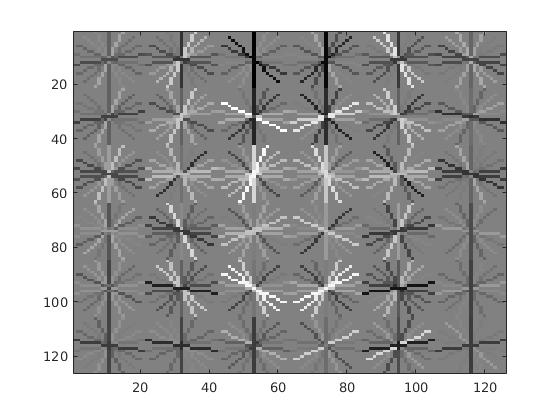 |
| 50000 | 85.3% | 13.55 |  |
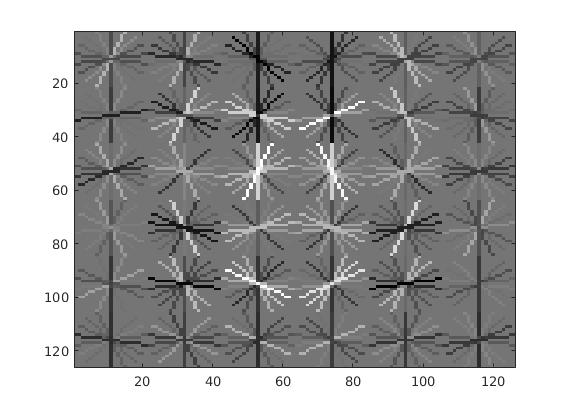 |
| 100000 | 86.2% | 24.99 |  |
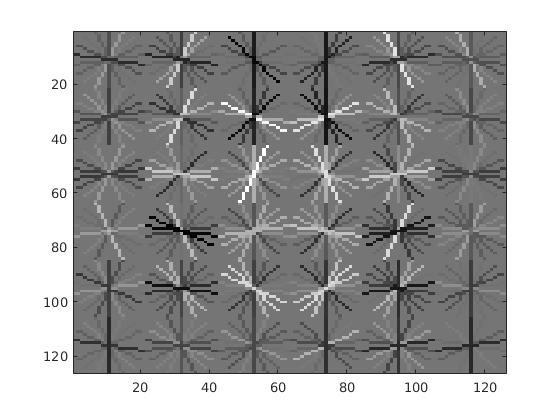 |
Extra Credit
Positive Training Data Augmentation
For extra credit, I added more positive training images from the Labeled Faces in the Wild Dataset
The dataset was built for an image recognition task and contains images of world famous figures. These images were colored and not in the same resolution as the default provided dataset.
Preprocessing
The dataset was first resized and then converted to grayscale images, using ImageMagick.
# The following is for images with names starting with A.
convert "A*.jpg[36x]" -background "#fff" -gravity Center -extent 36x36 A_resized%07d.jpg
convert "A_resized*" -set colorspace Gray "A_recolored%07d.jpg"
 |
 |
 |
 |
 |
 |
 |
 |
Results
The dataset was tested in the following two scenarios
- Using only the LFW dataset as the positive training dataset
- Using it in augmentation with the existing positive training set
A cell size of 3 and a negative sample size of 10000 was used in the below tests AP curve and HoG descriptor for the above scenarios:
| Only LFW |  |
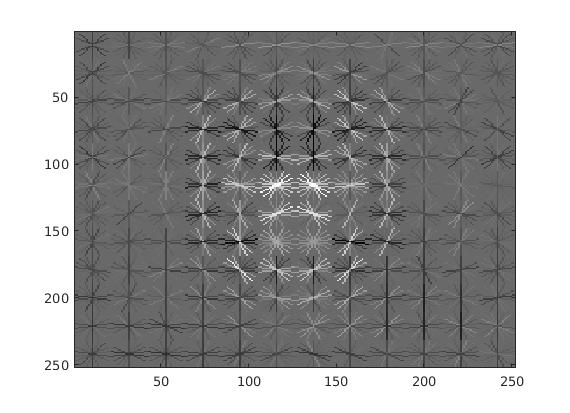 |
| Augmented LFW | 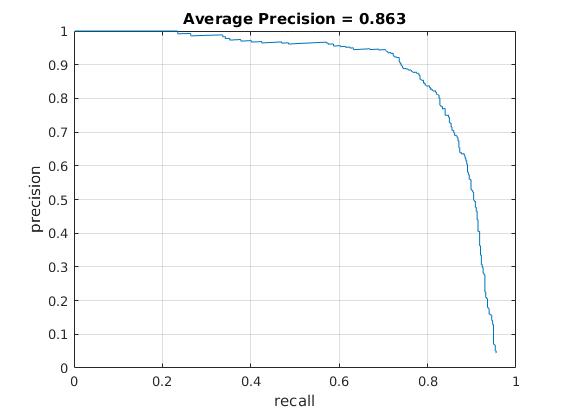 |
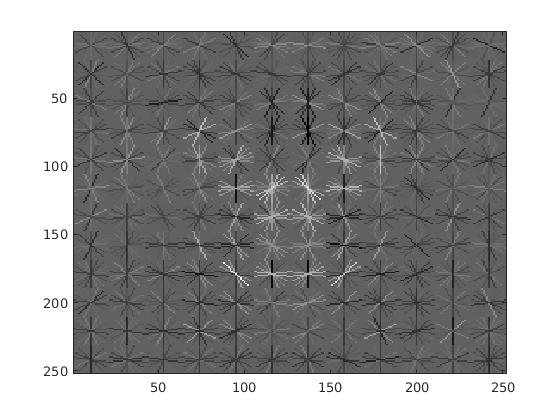 |
The extra dataset does not give comparable performance as compared to the provided dataset. When augmented with the existing positive dataset, the LFW dataset affects performance adversely bringing it down to 86.3% from 92%
A suspicion for the reason for poor performance is that the images are less scaled as compared to the provided dataset.
References
- Navneet Dalal, Bill Triggs. Histograms of Oriented Gradients for Human Detection. Cordelia Schmid and Stefano Soatto and Carlo Tomasi. International Conference on Computer Vision & Pattern Recognition (CVPR ’05), Jun 2005, San Diego, United States. IEEE Computer Society, 1, pp.886–893, 2005,
- R. K. McConnell. Method of and apparatus for pattern recognition, January 1986. U.S. Patent No. 4,567,610.
- Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. University of Massachusetts, Amherst, Technical Report 07-49, October, 2007.